
Komplexe Systeme in R
Wie baue ich komplexe Systeme mit R? Heute geht es darum, ein R-Projekt für komplexere Systeme zu organisieren. Diese gehen über ein simples Skript hinaus und deshalb muss man sich zur Struktur dieser Projekte etwas Gedanken machen. Der Post setzt einiges an Wissen voraus, also schau dir gerne nochmal die Basics an. Außerdem hilft dieser Post, welcher sich mit Funktionen in R befasst.
Komplexe Systeme in R
Einführung
Erstmal ist wichtig, was ich mit komplexen Systemen überhaupt meine. Ich denke hier an eine Sammlung von mehreren Komponenten, die miteinander verbunden sind. Stell dir ein System vor, das täglich automatisiert Daten herunterlädt und aufbereitet, diese dann analysiert oder zum Trainieren von Machine Learning-Modellen benutzt und anschließend einen Report generiert. Um solch ein System zu bauen, benötigt es eine durchdachte Architektur und Code muss in Funktionen ausgelagert werden. Je nach Größe des Projekts brauchen wir dafür mehrere Dateien.
System planen
Ziel des Systems
Unser System soll von einer Website die Top 50 Bands herunterladen und diese Daten anschließend aufbereiten und analysieren; das Resultat wird als Report in eine Textdatei geschrieben. Auf die Details werde ich heute nicht genauer eingehen, sondern stattdessen den allgemeinen Aufbau beschreiben.
Komponenten-Sicht
Der erste Schritt ist, das System in Komponenten aufzugliedern, die möglichst unabhängig voneinander funktionieren können. Für jede Komponente muss eindeutig sein, welche Inputs erwartet werden und welche Struktur diese Inputs aufweisen müssen.
Komponente „Datengrundlage“
Die erste Komponente heißt Datengrundlage und stellt aus verschiedenen Quellen einen standardisierten Datensatz zusammen. Der Output ist ein data.table mit folgenden Spalten:
- Position: Platzierung in der Top50 Liste
- Name: der Name der Band
- FoundingDate: das Gründungsdatum
- Genre: das Genre der Band
- Albums: Anzahl der veröffentlichten Alben
- Members: Anzahl der Mitglieder
Komponente „Analyse“
Hier sind Funktionen für das Analysieren des Datensatzes zu finden und als Output soll eine Liste mit mehreren Analysen erstellt werden:
- Metadaten zum Datensatz, wie die Anzahl der Reihen und Spalten und das Erstellungsdatum.
- Zusammenfassung zu den einzelnen Spalten.
- „Insights“, z.B. welches Genre am meisten vertreten ist.
Die Liste mit den Analysedaten kann anschließend von der Reporting-Komponente genutzt werden. Auch hier gilt wieder: Das ist der Analyse-Komponente eigentlich egal. Komponenten sollten unabhängig von anderen Komponenten funktionieren.
Komponente „Reporting“
Die Reporting-Komponente erwartet als Input eine Liste mit drei Analysen, welche jeweils wiederum selbst eine Liste mit Informationen sind. Aus dieser verschachtelten Datenstruktur wird ein Report gebaut, der in eine Textdatei geschrieben wird.
Struktur des Systems
Das System soll eine zentrale Stelle haben, die den Workflow verwaltet. Das heißt, dass die einzelnen Komponenten von dort aufgerufen werden und die Rückgabewerte an die nächste Komponente übergeben werden. Im folgenden Scribble ist die Systemarchitektur einfach dargestellt. Achja sorry, der Pfeil zur Festplatte HDD fehlt:
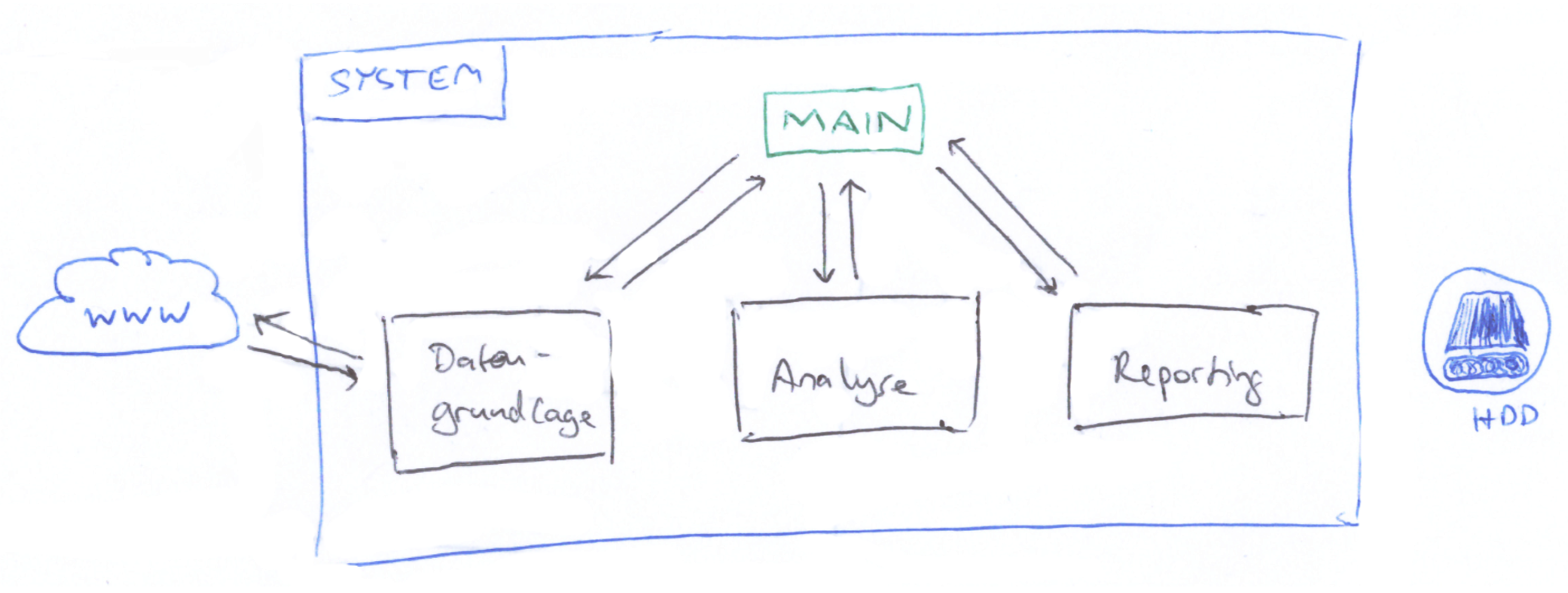
System mit R umsetzen
Wie kann ich nun ein solches System umsetzen? Das ist wesentlich einfacher, wenn man sich die Architektur wie oben einmal grob skizziert hat. So kommt man vielleicht auf folgenden Ansatz: Unsere Hauptdatei „main.R“ liegt im Hauptordner „system“ und greift später auf die weiteren Komponenten zu. Im Hauptordner erstellen wir außerdem für jede Komponente einen Unterordner: „data_basis“, „analysis“ und „reporting“. In diesen Ordnern können wir nun R-Dateien erstellen welche Funktionen beinhalten, die sich um eine bestimmte Sache kümmern: „metadata.R“, „columns.R“ und „insights.R“. Diese Überlegungen resultieren in folgender Struktur:
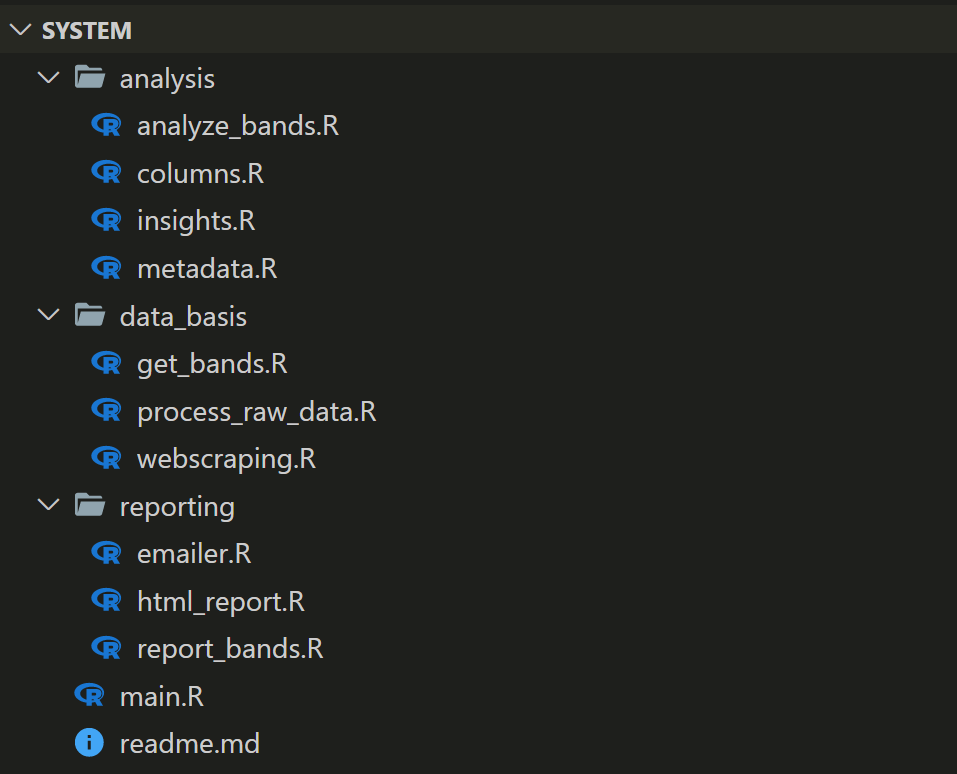
Wir sehen: Jede Komponente bzw. jedes Modul hat einen Unterordner. Die erste Datei soll hier die „Hauptdatei“ dieser Komponente darstellen. So greift die Datei get_bands.R auf Funktionen aus webscraping.R und process_raw_data.R zurück. Genauso bei der Analyse-Komponente: analyze_bands.R nutzt Funktionen aus drei weiteren Dateien. Die Datei „metadata.R“ könnte z.B. folgendes beinhalten:
#Returns a list with metadata for the current dataset
analyze_metadata <- function(dataset) {
n_rows <- nrow(dataset)
n_cols <- ncol(dataset)
date_of_analysis <- today()
metadata <- list(Rows=n_rows, Columns=n_cols, CreationDate=date_of_analysis)
return(metadata)
}Und so weiter.
Für das vorgestellte Projekt mag das etwas viel Overhead sein, aber ich möchte hiermit ja auch nur eine Code-Organisation für komplexere Systeme darstellen. Die Vorteile sind unter anderem:
- Die Komponenten/Module sind unabhängig voneinander, sodass man diese auch in anderen Projekten benutzen könne. Man könnte auch einzelne eigene Packages bauen, aber das würde hier den Rahmen sprengen.
- Man hat mehr Übersicht und weiß, wo man welche Funktionen finden kann.
- Eine gute Struktur zwingt einen, guten Code / „clean code“ zu schreiben.
- Und dadurch ist der Code einfach erweiterbar.
Der Workflow
In der main.R-Datei werden die Hauptfunktionen der Komponenten aufgerufen. Übrigens: Es spricht nichts dagegen, jede Hauptdatei in den Subordnern init.R zu nennen, denn so wäre es eindeutig, wo die Hauptfunktionen liegen.
Doch eine Sache ist noch wichtig: Am Anfang der main.R werden via source die Hauptdateien der Komponenten geladen und diese enthalten wiederum source-Befehle für die Komponenten-internen Dateien. Schau dir den Aufbau an:
#Main file for bands project
#Source components
source("data_basis/get_bands.R")
source("analysis/analyze_bands.R")
source("reporting/report_bands.R")
#Run workflow
data <- get_bands()
analyses <- analyze_bands(data)
report_bands(analyses, sendmail=TRUE)Der Code verdeutlicht gut, wie das System strukturiert ist. Die main.R muss sich offensichtlich nicht um Details kümmern – sie orchestriert nur die verschiedenen Komponenten. Die Komponenten wiederum stellen Hauptfunktionen zur Verfügung und diese sind so geschrieben, dass sie einfach zu bedienen sind. Einige dieser Funktionen haben Parameter, die uns bestimmte Optionen steuern lassen (z.B. sendmail für die dritte Funktion). Und damit wäre das Wichtigste zum Aufbau eines solchen Systems gesagt!
Noch Fragen?
Dieser Post ist mal etwas anders gewesen, denn es handelte sich eher um Architektur und Projektorganisation als um die Programmierung mit R selbst. Hinterlasse gerne einen Kommentar, wenn es dir gefallen hat oder du dir etwas anderes wünschst. Würde dich vielleicht ein bestimmtes Projekt oder System interessieren, oder hast du ein spezifisches Problem, das du lösen musst? Dann sag gern Bescheid!
Beste Grüße





Ich bin ein absoluter Anfänger, studiere Psychologie und liebäugele mit Datascience. Ich hab manchmal das Problem, dass das Coding meist bei Grundlagen anfängt, die wirklich mit drücken sie hier und drücken sie da starten, ohne den Zusammenhang im Sinne von wozu macht man das, zu erläutern. Die ersten Schritte in R waren grausam, bis man Infos dazu gefunden hatte überhaupt wie die Ordnerstruktur auszusehen hat und was ein Workspace ist und welche Bedeutung das hat. Das ist das eine. Deswegen dieser Post hier – klasse, so als Ausblick, damit man ein wenig versteht was was ist, zu welchem Zweck und in welchem Zusammenhang und welche Folgen das für das Coding haben kann.
Die andere Sache noch, ich verstehe allmählich die Logik de Funktionen und der Blöcke und Schleifen, aber die Syntax, die macht mich fertig. Woher weiss ich denn wie ich die Argumente zu schreiben habe und welche, und jeder Nutzer setzt in seine Codes von Funktionen jeweils andere Zeichen als Syntaxausdruck. Wie ist denn das zu handhaben?
(Ich gucke mir noch mal den Post zu der Syntax an…)