
Plots – Die Basics
„Ein Bild sagt mehr als tausend Worte“
Ein perfektes Sprichwort für das heutige Thema: Graphen bzw. „Plots“. Gerade zum Präsentieren von Ergebnissen statistischer Analysen sind sie unabdingbar. Eine Sache vorweg: Richtig schöne und komplexere Plots ermöglicht das Extra-Package ggplot2, das wiederum einen eigenen Post in der Zukunft verdient. Heute gehe ich nur auf die Möglichkeiten ein, die das base package liefert (welches bereits installiert ist und nicht zusätzlich geladen werden muss).
Für einen schnellen Überblick liste ich hier schonmal die verschiedenen Plots, die ich bespreche:
– Histogramme: Um für eine numerische Variable ein Histogramm zu erstellen, benutzen wir hist(…).
– Boxplots: Diese werden mit boxplot(…) erstellt.
– Scatterplots: Für die Visualisierung von zwei numerischen Variablen können wir einfach plot(…) benutzen.
– Balkendiagramme: Um die Abhängigkeit einer numerischen von einer kategorischen Variable darzustellen, benutzen wir barplot(…).
– Tortendiagramme: Werden einfach mit pie(…) geplottet.
Gerade bei bestimmten Chart-Packages wie ggplot2 gibt es noch viele weitere Möglichkeiten, für heute reichen uns die fünf oben genannten Plots.
Plots für eine numerische Variable
Fangen wir mit Diagrammen an, die sich nur auf eine Variable beziehen. Wir erstellen einen Vektor x, der 100 Zufallswerte von einer Normalverteilung enthält (mit einem Mittelwert von 10 und einer Standardabweichung von 2): x <- rnorm(100, 10, 2). Das reicht auch schon, um zwei einfache Plots vorzustellen: hist(x), und boxplot(x). Wir sehen: Die erstellen Plots sind zwar informativ, aber bei weitem nicht schön anzusehen. Ein paar Änderungen lassen sich aber auch für diese einfachen Plots machen.
So können wir ein paar Parameter für die hist-Funktion ändern:
- col: Die Farbe der bars
- main: Der Titel des Graphen
- xlab: Label der x-Achse
- ylab: Label der y-Achse
- probability: Wenn TRUE, dann werden keine Häufigkeiten, sondern Proportionen angezeigt
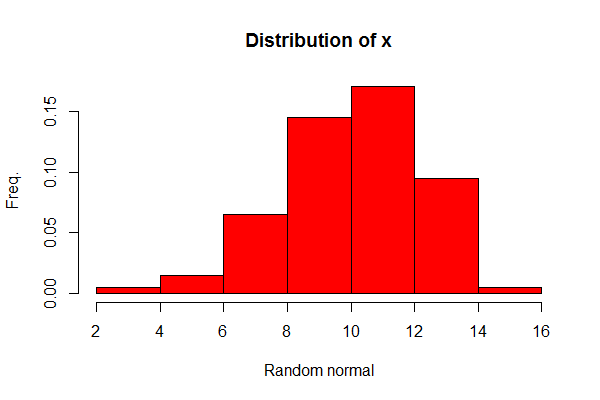
Beispiel: hist(x, col="red", main="Distribution of x", xlab="Random normal", ylab="Freq.", probability=TRUE). Es lassen sich noch weitere Parameter ändern; einen Einblick kriegen wir, wenn wir uns die Dokumentation unter ?hist anzeigen lassen.
Plots für eine kategorische Variable
Auch für kategorische Variablen haben wir verschiedene Möglichkeiten. Für Balkendiagramme benutzen wir barplot. Beispiel: barplot(1:3). Wir übergeben hier an die Funktion einen Vektor mit den Werten 1, 2, und 3. Entsprechend gibt es drei Balken mit den jeweiligen Höhen. Für ein Tortendiagramm benutzen wir pie. Beispiel: pie(c(1,4,5)).
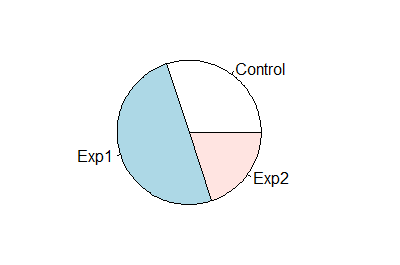
Diese Möglichkeiten können wir uns zunutze machen, wenn wir zum Beispiel Häufigkeiten darstellen möchten. Angenommen wir haben einen Vektor der Länge 100 mit drei verschiedenen Kategorien (z.B. Gruppen in einem Experiment), so können wir uns die Häufigkeiten auch ganz einfach darstellen lassen. Für unser Beispiel erstellen wir einen Vektor des Typs factor (siehe hier für die verschiedenen Typen eines Vektors):
fact <- rep(1, 100)
fact[x >= 9] <- 2
fact[x >= 12] <- 3
fact <- factor(fact, labels=c("Control", "Exp1", "Exp2"))Einfach barplot(fact) eingeben wird allerdings nicht funktionieren, da der Funktion ganz klar gesagt werden muss, was für Werte sie anzeigen soll. Also benutzen wir ganz einfach die Funktion table, welche uns die Häufigkeiten der Elemente in einem Vektor ausgibt: freqTable <- table(fact). Wir können uns jetzt übrigens auch eine "proportion table" erstellen, welche die Proportionen der Elemente anzeigt: propTable <- prop.table(freqTable). Beachte, dass man hier die bereits erstellte table als Argument angeben muss. So, nun haben wir alle Vorbereitungen getroffen (war ja nicht viel) und können einen Plot erstellen: barplot(freqTable), oder wer die Prozente an der Seite stehen haben möchte: barplot(propTable). Genauso können wir unser freqTable-Objekt an die pie-Funktion übergeben: pie(freqTable).
Plots für die Abhängigkeit zweier numerischer Variablen
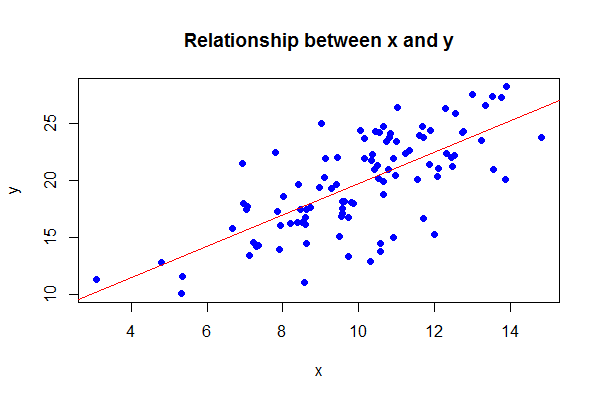
Um einen Plot zu erstellen, der den Zusammenhang zwischen zwei numerischen Variablen darstellt, brauchen wir eine weitere Variable, die wir nun von x abhängig machen: y <- 4.2 + 1.58 * x + rnorm(100, 0, 3). Wir sehen, ein bisschen "Fehler" habe ich hinzugefügt, damit die Korrelation nicht perfekt ist: cor(x, y). Nun haben wir eine weitere Variable y, die stark mit x korreliert. Dies lässt sich ganz einfach darstellen: plot(x, y) (man kann übrigens auch die "Formel-Schreibweise" verwenden: plot(y ~ x), sprich "y ist abhängig von x"). Auch hier gilt: Wir können den Plot etwas aufwerten, indem wir zum Beispiel die Parameter pch oder wieder col verändern: plot(x, y, pch=16, col="blue", main="Relationship between x and y"). Der Parameter pch bestimmt übrigens den Typen des Punktes (siehe ?par für weitere Infos zu den grafischen Parametern, die für grafische base-Funktionen wie z.B. plot gelten).
In einem Plot, der den Zusammenhang zwischen zwei numerischen Variablen darstellt, möchten wir häufig die Regressionslinie anzeigen. Auch das geht in R sehr einfach: Zuerst erstellen wir Das Regressionsmodell: mdl <- lm(y ~ x). Die Funktion lm (für "linear model") rechnet eine Regression für die Angegebene Formel y ~ x. Anschließend können wir unseren Plot verfeinern, indem wir folgendes ausführen: abline(mdl). Die Funktion abline weiß hier offensichtlich, was zu tun ist mit dem Regressionsobjekt mdl, das wir oben berechnet haben.
Plots für den Zusammenhang zwischen einer numerischen Variable und einem Faktor
Häufig möchten wir z.B. den Mittelwert von verschiedenen Gruppen vergleichen. Die statistische Analyse würde hier ein einfaches ANOVA-Modell erfordern. Wie können wir aber die Gruppen vernünftig plotten? Eine Möglichkeit Gruppen auf einen numerischen Wert zu vergleichen bietet boxplot. Hier geht es zwar noch nicht um Mittelwertsvergleiche, aber für eine visuelle Inspektion durchaus hilfreich: boxplot(x ~ fact). Hier machen wir x abhängig von unser oben erstellten kategorischen Variable fact. Wir sehen drei Boxplots, einer für jede Gruppe von fact. Um Mittelwerte zu vergleichen müssen wir diese zuerst berechnen. Das können wir mit der by-Funktion machen. Hierbei wird für einen bestimmten Vektor je Gruppe eine bestimmte Funktion ausgeführt. Beispiel: by(x, fact, mean). Wir sehen: Die Funktion mean wird je Gruppe, definiert durch fact, für den Vektor x ausgeführt; wir erhalten drei Mittelwerte. Diese Funktion betten wir einfach in der bereits bekannten barplot-Funktion ein: barplot(by(x, fact, mean)). Voilà, wir haben einen "means plot" erstellt!
Mit diesem Plot hört der Post nun auf; die Basics sollten jetzt bekannt sein: das erstellen verschiedener Plots je nach Anforderungen, und das Wissen, wie man Plots etwas aufwertet durch das Ändern von Farben oder Symbolen. Bei Weitem ist das noch nicht alles, was R bzgl. grafischem Output leisten kann - aber dazu mehr in einem zukünftigen Post.
Was würde dich besonders interessieren bzgl. Erstellen von Graphen in R? Kommentiere oder schreib eine E-Mail: mail@r-coding.de.
Bleib außerdem auf dem Laufenden mit dem r-coding Newsletter. Du erhältst Infos zu neuen Blogeinträgen, sowie kleine Tipps und Tricks zu R. Melde dich jetzt an: http://r-coding.de/newsletter.
Viel Erfolg!





Hi, du wolltest mal einen Blog zu ggplot2 machen. Würde mich freuen, wenn das klappt!
Hi Michel, danke für die Rückmeldung – gerne setze ich mich da als nächstes ran. Hast du einen Wunsch, was ich in dem Post mit abdecken könnte? Beste Grüße