Data Frames – Zweiter Teil
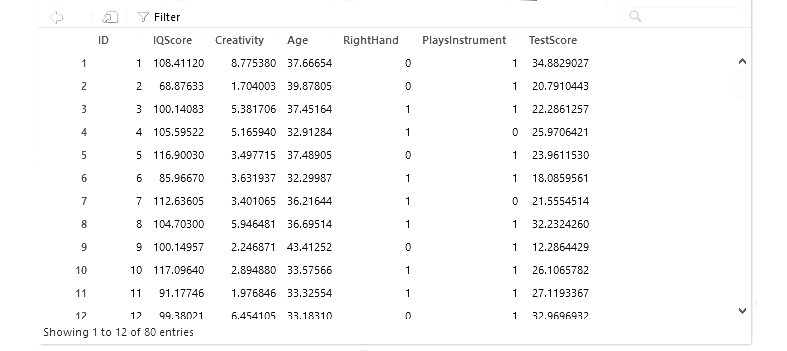
Moin! Im letzten Post haben wir den data.frame kennengelernt und einen künstlichen Datensatz erstellt – bestimmte Eigenschaften von 80 Personen inklusive Testergebnis, welches von fast allen Eigenschaften abhängig war. In diesem Post werden wir schauen, wie die data.frame-Notation aussieht und einige nützliche Funktionen kennenlernen.
Allgemeine Eigenschaften
Ein data.frame hat eine bestimmte Anzahl an Reihen und Spalten. Mit einem einfachen Befehl lässt sich dies herausfinden: dim(dfSurvey). Diese Funktion liefert einen Vektor mit zwei Elementen – Anzahl der Reihen und Anzahl der Spalten. Die Anzahl der Reihen lässt sich auch mit nrow(dfSurvey) herausfinden; die Anzahl der Spalten mit ncol(dfSurvey).
Als nächstes können wir uns die Namen der Spalten anzeigen lassen: names(dfSurvey). Diese Funktion gibt einen character vector zurück mit den entsprechenden Namen. Wir können uns zum Beispiel gezielt anschauen, welche Variable an Stelle 4 im Datensatz steht: names(dfSurvey)[4].
Subsetting
Um mit Datensätzen gut hantieren zu können, muss man wissen, wie man nur bestimmte Teile im Datensatz anspricht. Im letzten Post hatten wir bereits gesehen, dass wir eine Spalte direkt über den Namen als Vektor ausgeben lassen können: dfSurvey$IQScore. Wir können auch gezielt bestimmte Einträge im jeweiligen Vektor anzeigen lassen: dfSurvey$Creativity[5], oder dfSurvey$Age[1:10]. Im zweiten Beispiel wählen wir die ersten zehn Einträge aus, was wir dadurch erreicht haben, dass wir 1:10 in die eckigen Klammern geschrieben haben (was wiederum ein Vektor ist; man hätte auch mühselig folgendes schreiben können: dfSurvey$Age[c(1,2,3,4,5,6,7,8,9,10)]).
Bei einem Vektor müssen wir nur eine Zahl angeben, wenn wir ein bestimmtes Element auswählen möchten. Da ein data frame zweidimensional ist, können wir hier sowohl für die Reihe als auch für die Spalte einen Wert angeben. Hier gilt: Zuerst die Reihennummer, dann die Spaltennummer – beispielsweise von der ersten Person (= erste Reihe) der IQ-Wert (= zweite Spalte): dfSurvey[1,2]. Lassen wir an einer Position die Zahl absichtlich weg, so werden alle entsprechenden Elemente angezeigt: dfSurvey[7,]. Hier sehen wir, dass die gesamte siebte Reihe zu sehen ist. Soll die gesamte siebte Spalte zu sehen sein, müssen wir die 7 an die zweite Position schreiben, da wir so die Spalte(n) auswählen: dfSurvey[,7]. Wir müssen nicht nur einen Wert für eine Position übergeben; wir können auch mehrere Reihen (oder Spalten) auswählen. Beispiel: dfSurvey[c(1,4,7,11),] oder dfSurvey[,c(1,5,6)].
Daten trennen und zusammenführen
Über das Auswählen von sogenannten Subsets (= Subsetting) können wir bestimmte Daten in neuen Objekten speichern lassen, die für uns gerade interessant oder relevant sind. Im Folgenden zeige ich ein kurzes Beispiel für das Trennen der Daten nach Reihe und anschließendes Zusammenführen. Zuerst erstellen wir einen Datensatz, der nur die ersten 40 Personen enthält: dfSurveyFirstHalf <- dfSurvey[1:40,]. Das gleiche mit der zweiten Hälfte: dfSurveySecondHalf <- dfSurvey[41:80,]. Jetzt haben wir zwei separate Datensätze. Möchten wir diese wieder zusammenführen, so benutzen wir die Funktion rbind (für "row bind"): dfSurveyFull <- rbind(dfSurveyFirstHalf, dfSurveySecondHalf). Das gleiche kann man übrigens auch für das Hinzufügen von Spalten zu einem Datensatz mit cbind ("column bind") machen.
Summen und Mittelwerte
Zum Schluss möchte ich noch vier hilfreiche Funktionen vorstellen, die man auf den gesamten Datensatz anwenden kann. Möchte man über eine gesamte Reihe eine Summe bilden (und dies für alle Reihen), so benutzt man rowSums: rowSums(dfSurvey). Man muss hier beachten, dass die Funktion tatsächlich jede Spalte miteinbezieht; deshalb müssen alle Variablen numerisch (oder ganzzahlig) sein. Möchte man statt einer Summe einen Mittelwert, benutzt man einfach rowMeans: rowMeans(dfSurvey). Diese Funktionen sind besonders hilfreich, wenn man aus einzelnen Items einen Gesamtscore berechnen muss. Die Funktionen gibt es genauso je Spalte: colSums und colMeans.
Soweit heute mit dem zweiten Teil für Data Frames! Mit diesem Wissen sollte schon vieles möglich sein und gleichzeitig ist es Grundlage für vieles, das noch folgt. Viel Erfolg damit!