
Das data.table Package
Heute geht es um das data.table Package, welches uns viele Operationen vereinfacht. Was unterscheidet data.table von data.frame? Was für Funktionalitäten bietet es?
Aber kurz vorweg: nach langer Zeit melde ich mich wieder zurück. Ein Danke an alle, die den Blog früher gelesen hatten; es motiviert mich, diesen Blog weiterzuführen, da ich über die letzten Jahre durchaus einige Rückmeldungen bekam, warum es denn keine neuen Posts gibt. Zeitlich hat sich bei mir mittlerweile wieder einiges getan, sodass ich nun wieder regelmäßig neue Beiträge hochladen möchte. Und wie schon geschrieben, geht es heute um das data.table Package (siehe Github). In früheren Posts habe ich data.frame erklärt und ich gehe hier davon aus, dass du damit etwas vertraut bist. Denn das data.table-Package baut auf data.frame auf und liefert viele hilfreiche Funktionalitäten. Fangen wir an!
Grundlagen
Im Folgenden werden wir erst einmal die absoluten Basics behandeln.
Installieren von data.table
Solltest du das Package noch nicht haben, musst du es zuerst installieren. Das geht ganz einfach mit dem Befehl: install.packages("data.table").
Die Library data.table laden
Um data.tables benutzen zu können, muss die Bibliothek (= Library) geladen sein. Das Laden von Libraries sollte man grundsätzlich an den Anfang des Codes setzen, damit andere (und auch man selbst!) schnell sehen können, was geladen (und ggf. vorher installiert) sein muss. Das Laden von data.table ist denkbar einfach: library(data.table).
Ein data.table erstellen
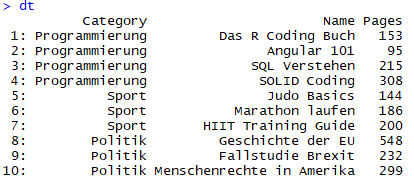
Eine Tabelle lässt sich genauso wie bei data.frame erstellen, z.B.: dt <- data.table(ID=1:10). Wir können auch ein vorhandenes Data Frame benutzen und es zu einem Data Table konvertieren (df ist hier das Data Frame): dt <- as.data.table(df). In dem Beispiel (s.u.) erstellen wir vorerst eine Tabelle mit 10 Zeilen und zwei Spalten. Es geht um Bücher, die einer bestimmten Kategorie zugeordnet sind.
Spalten im data.table erstellen und entfernen
Neue Spalten lassen sich ganz einfach hinzufügen, aber die Syntax ist hier anders als bei data.frame! Wir benutzen den := Operator in folgender Schreibweise: dt[, NeueSpalte := xyz]. In dem Beispiel wird die Anzahl der Seiten hinzugefügt. Wir fügen eine weitere Spalte ID hinzu: dt[, ID := sequence(.N)]. Wir sehen hier bereits etwas, was data.table mitbringt: das .N berechnet automatisch die Anzahl der Zeilen, somit müssen wir uns darum nicht kümmern und der Code wird immer eine richtige ID-Spalte erstellen, die von 1 bis N zählt. Übrigens: Eine Spalte löschen kann man ganz einfach mit := NULL (dt[, ID := NULL]).
Die Tabelle müsste nun wie folgt aussehen:
Selektieren von Daten in data.table
Selektieren geht ganz einfach, indem wir in die eckigen Klammern die Bedingungen schreiben: dt[Pages >= 300]. In dem Beispiel wählen wir nur Bücher mit mindestens 300 Seiten aus. Wir können übrigens auch eine neue Variable erstellen, die aber vom Wert einer anderen abhängig ist, z.B.: dt[, IsLongBook := as.integer(Pages >= 300)]. Die neue Spalte IsLongBook ist nun 1, wenn die Anzahl der Seiten mindestens 300 ist.
Daten aggregieren
In diesem Abschnitt schauen wir uns an, wie man Funktionen auf Gruppen von Daten anwenden kann.
Gruppieren in data.table
Nun kommen wir zu einer sehr hilfreichen Funktionalität von data.table: Gruppieren. Wir können bestimmte Operationen eben je Gruppierung durchführen, indem wir ganz einfach das by-Argument benutzen. Wie in diesem Code: dt[, PagesPerCategory := sum(Pages), by="Category"]. Hier berechnen wir die Summe der Bücherseiten, aber eben je Kategorie und speichern diese in einer neuen Spalte. Darauf aufbauend können wir nun z.B. schauen, wie viel % der Gesamtseiten in der Kategorie durch das jeweilige Buch gedeckt werden: dt[, PercentInCategory := 100 * round(Pages / PagesPerCategory, 4)].
Aggregieren in data.table
Wir können unseren Datensatz auch reduzieren und nur aggregierte Werte je Gruppe erstellen. Manchmal braucht man die Werte je Gruppe nicht mehr im gesamten Datensatz, sondern es reicht, den kleineren, aggregierten Datensatz zu haben. Auch das ist ganz einfach:
#Aggregate to category level
dtCategory <- dt[, list(
Books = .N,
PagesTotal = sum(Pages),
PagesAvg = mean(Pages)
), by = "Category"]Wie man sieht, benutzen wir eine Kombination aus list(...) und by=..., um den aggregierten Datensatz zu erstellen. Im vorliegenden Fall sind .N, sum und mean die Funktionen fürs Aggregieren. Wir bemerken auch, dass data.table automatisch .N auf die Gruppierung bezieht.
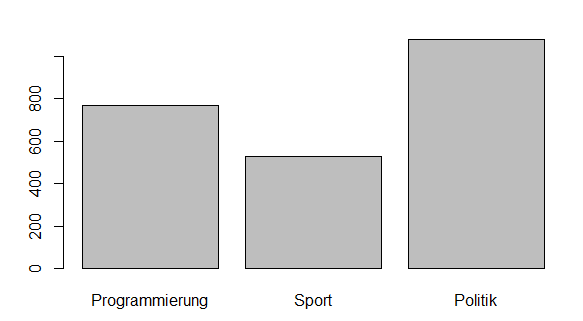
Ein Barplot von den aggregierten Daten:
Weitere data.table Funktionen
Das Package data.table kann noch mehr. Einige Beispiele:
- Keine direkte Funktion vom Package, aber sehr hilfreich, um nach mehreren Dingen zu filtern:
dt[Category %in% c("Sport", "Politik") & nchar(Name) > 20](nimmt nur Bücher aus Sport und Politik mit Titel, die länger als 20 Buchstaben sind) - Benutzen von Funktionen als by-Argument:
dt[, .(Med = median(Pages), SD = sd(Pages)), by=(nchar(Name) > 15)](Gruppierung, ob der Titel länger als 15 Zeichen ist - aggregiert Median und Standardabweichung von der Seitenanzahl) - Aggregieren von ausgewählten Spalten mit .SD und .SDcols:
dt[, lapply(.SD, sum), .SDcols=c("Pages", "PercentInCategory"), by="Category"](Summieren der angegebenen Spalten je Kategorie)
Ein weiteres Beispiel noch; hier sehen wir, wie man den Datensatz reduziert und in einem neuen speichert, in diesem anschließend Spaltennamen ändert, die Reihenfolge der spalten anpasst und die Fälle sortiert:
#Use of 'set' functions
dtReduced <- dt[, .(Category, Name, Pages)]
setnames(dtReduced, c("BookCategory", "BookName", "BookPages"))
setcolorder(dtReduced, c("BookName", "BookCategory", "BookPages"))
setorder(dtReduced, -BookPages)Das war's mit der Einführung in data.table. Ich werde dieses Package mit Sicherheit in weiteren Tutorials benutzen. Ich empfehle auf jeden Fall, data.table statt data.frame zu verwenden, da man viel mehr Möglichkeiten hat und der Code meistens lesbarer ist - auch wenn man sich erstmal an die Syntax gewöhnen muss.
Viel Erfolg!






Ein Kommentar